Lab: file system
In this lab you will add large files and symbolic links to the xv6
file system.
Before writing code, you should read "Chapter 8:
File system" from the xv6
book and study the corresponding code.
In this lab, there are several questions for you to answer. Questions are in boxes with a light orange background.
Write each question and its answer in your notebook. You will state the percentage of questions answered on your lab submission.
The Linux grep command can be helpful on some questions. For example, suppose a question asks you about the struct proc. You can discover the definition and uses of the struct proc by issuing the following Linux grep command in the kernel directory.
$ grep inode *.h
defs.h:struct inode;
defs.h:int dirlink(struct inode*, char*, uint);
defs.h:struct inode* dirlookup(struct inode*, char*, uint*);
... lots of matches
fs.h:#define IBLOCK(i, sb) ((i) / IPB + sb.inodestart)
proc.h: struct inode *cwd; // Current directory
% grep inode *.c
exec.c:static int loadseg(pde_t *, uint64, struct inode *, uint, uint);
exec.c: struct inode *ip;
exec.c:loadseg(pagetable_t pagetable, uint64 va, struct inode *ip, uint offset, uint sz)
... lots of matches
sysfile.c: struct inode *ip;
sysfile.c: struct inode *ip;
Fetch the xv6 source for the lab and check out the fs branch:
$ git fetch
$ git checkout fs
$ make clean
Introduction
1. We know there are disk inodes and in-memory inodes. This question is more general. Describe an inode in your own words.
2. Why do we have disk inodes and in-memory inodes?
3. Inodes (both disk and in-memory) do not contain filenames. Where are filenames and how are they related to inodes?
4. We know the RAM is a sequence of bytes, where each byte has a physical address. Compare RAM and disks.
5. Suppose that our file system has disk blocks that are 1024 bytes and a disk inode is 64 bytes.
Our file system has allocated blocks 7, 8, and 9 to store disk inodes.
- How many files does our filesystem support?
- Given we need to read the file associated with inode number 70, how do we get the inode from the disk?
6. Suppose that our file system has disk blocks that are 1024 bytes and the following is the format of our disk inode,
which does not have any indirect blocks is the following.
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[8]; // Data block addresses
};
What is the maximum number of bytes a file can be?
7. Suppose that our file system has disk blocks that are 1024 bytes and the following is the format of our disk inode,
where addrs[8] is an indirect block.
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[9]; // Data block addresses
};
What is the maximum number of bytes a file can be?
8. How does a filesystem support multiple filenames referencing the same data?
9. How does the open system call reference a file?
10. How does the read system call reference a file?
11. How does a directory entry reference file?
12. What are three ways to reference a file?
13. Consider the following C code snippet.
int main(int argc, char **argv) {
int fd = open("file", O_RDONLY);
...
}
What is the value of
fd and why?
14. Consider the following ls command, which I entered on our CPSC server. The command displays information about a file that is stored in the file's inode.
$ ls -l file.c
-rw-r--r-- 1 gusty faculty 3609 Apr 22 2024 file.c
- The first dash (-) signifies it is a regular file.
- A file has three access permissions: read (r), write (w), and execute (x). The rw-r--r-- signifies the owner has read-write, the group has read, and other has read access to the file.
- The 1 signifies there is one link to the file.
- The gusty signifies that gusty owns the file.
- The faculty signifies that gusty is in the faculty group.
- The 3609 signfies that file.c is 3609 bytes.
- The Apr 22 2024 is the date the file was last modified.
- The file.c is the file name.
- Which of these items can Xv6 display?
- What is the system call that can change the number of links to the file?
15. Consider the following echo and pwd commands, which I entered on our CPSC server.
The commands and output have line numbers so I can reference them for questions.
The echo command shows I am using the bash (or Bourne Again) Shell.
Ken Thompson ahd Dennis Ritchie (both at Bell Labs) were the original developers of Unix.
Unix Version 6 (released in 1975) was the first version widely distributed, and it is the basis of our Xv6 OS.
Ken Thompson wrote the first shell, which was in the file sh.c.
Our Xv6 user/sh.c is similar to the original Thompson shell.
Stephen Bourne (of Bell labs) wrote the Bourne shell, which was included in the 1979 release Unix Version 7 in the file sh.c.
Brian Fox of the GNU project wrote the Bourne Again shell as a completely open version of the Bourne shell.
The bash shell was released in 1989. bash is the default shell for most Linux and Unix distriubtions.
1 $ echo $SHELL
2 /bin/bash
3 $ pwd
4 /home/faculty/gusty/xv6-labs/kernel
5 $ cd ..
6 $ pwd
7 /home/faculty/gusty/xv6-labs
- Notice how the pwd commands on lines 3 and 6 show different current working directories.
In which OS data strcuture is the current working directory stored?
- Notice the .. on the cd command on line 5.
What is .. and where is it stored?
16. When a process starts, what are file descriptors 0, 1, and 2?
17. Consider the following ls command, which I entered on our Xv6 system.
$ ls README
README 2 2 2305
If you examine the code in
ls.c, you will discover the following line of code displays the
ls results.
printf("%s %d %d %l\n", fmtname(path), st.type, st.ino, st.size);
If you examine the code in
printf.c, you will discover the following line of code is used to display each character.
write(1, &c, 1);
Explain how the following
ls shell command places the
output into a file, even though it uses the exact same printf and write statements as shown above.
$ ls README > file
$ cat file
README 2 2 2305
20. Both open and pipe system call return file descriptors. Compare files and pipes.
21. Xv6 does not have a rename system call. Describe what you would have to do to implement rename. I am not looking for the details of how to add a system call to Xv6. I just want you to describe what has to happen for a file to be renamed.
22. Suppose that our file system has disk blocks that are 1024 bytes and the filesystem has 32,768 total blocks. We allocate block 1 to the super block, block 2 to the log head, blocks 3 to 31 to log blocks, and blocks 32 to 44 to inodes. How many blocks must we allocate to the bitmap in order to use the remaining blocks as data blocks.
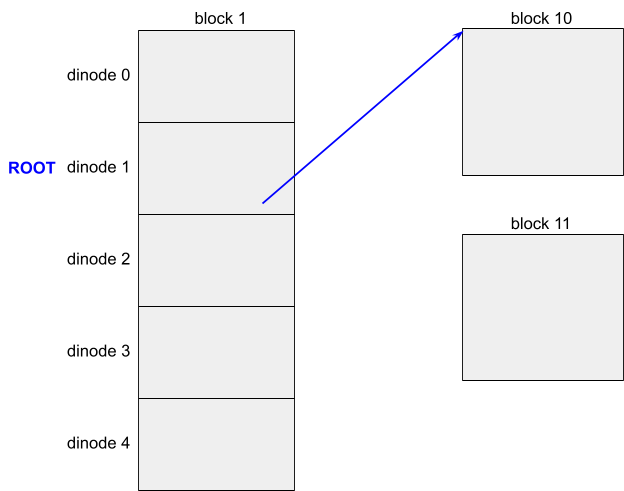
23. Consider the following diagram of a tiny filesystem. The dinodes are on block 1. The ROOT directory is allocated to dinode 1. Data blocks begin at block 10. Redraw the diagram in your notebook, and complete it for the file /file, which has your name as its content. Assume that block 11 is allcated as the data block for file.
24. Consider the following diagram of a struct proc and its corresponding file data structures.
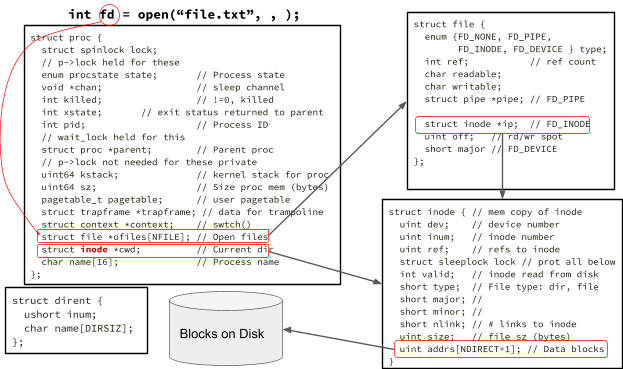
Explain the diagram in your own words.
Problem 1: Large files
In this assignment you'll increase the maximum size of an xv6
file. Currently xv6 files are limited to 268 blocks, or 268*BSIZE
bytes (BSIZE is 1024 in xv6). This limit comes from the fact that an
xv6 inode contains 12 "direct" block numbers and one "singly-indirect"
block number, which refers to a block that holds up to 256 more block
numbers, for a total of 12+256=268 blocks.
You'll change the xv6 file system code to support a
"doubly-indirect" block in each inode, containing 256 addresses of
singly-indirect blocks, each of which can contain up to 256 addresses
of data blocks. The result will be that a file will be able to consist
of up to 65803 blocks, or 256*256+256+11 blocks (11 instead of 12, because we will
sacrifice one of the direct block numbers for the double-indirect
block).
Preliminaries
The mkfs program creates the xv6 file system disk image
and determines
how many total blocks the file system has; this size is controlled by
FSSIZE in kernel/param.h.
You'll see that FSSIZE in the repository for
this lab is set to
200,000 blocks. You should see the following output from mkfs/mkfs
in the make output:
nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000
This line describes the file system that mkfs/mkfs built: it
has 70 meta-data blocks (blocks used to describe the file system) and
199,930 data blocks, totaling 200,000 blocks.
If at any point during the lab you find yourself having to rebuild the file system from scratch, you
can run make clean which forces make to rebuild fs.img.
What to Look At
The format of an on-disk inode is defined by struct dinode
in fs.h. You're particularly interested in NDIRECT,
NINDIRECT, MAXFILE, and the addrs[] element
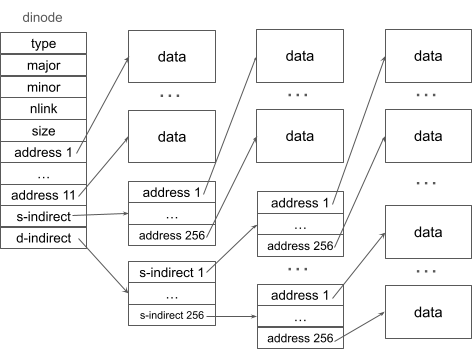
of struct dinode. The following figure is an updated version
of Figure 8-3 in the xv6 book.
It shows a dinode with
direct, singly-indirect, and doubly-indirect blocks.
You should compare this diagarm with Figure 8-3. You should notice
that the size of a struct dinode did not change. The dinode
in Figure 8-3 has 12 direct addresses and one singly-indirect. The dinode
in the following figure has 11 direct addresses, one singly-indirect, and
one doubly-indirect.
If you understand
this diagram, you are well on the way to solving this problem.
The code that finds a file's data on disk is in bmap()
in fs.c. Have a look at it and make sure you understand
what it's doing. bmap() is called both when reading and
writing a file. When writing, bmap() allocates new
blocks as needed to hold file content, as well as allocating
an indirect block if needed to hold block addresses.
bmap() deals with two kinds of block numbers. The bn
argument is a "logical block number" -- a block number within the file,
relative to the start
of the file. The block numbers in ip->addrs[], and the
argument to bread(), are disk block numbers.
You can view bmap() as mapping a file's logical
block numbers into disk block numbers.
Your Job
Modify bmap() so that it implements a doubly-indirect block,
in addition to direct blocks and a singly-indirect block. You'll have
to have only 11 direct blocks, rather than 12, to make room for your
new doubly-indirect block; you're not allowed to change the size of an
on-disk inode. The first 11 elements of ip->addrs[] should
be direct blocks; the 12th should be a singly-indirect block (just
like the current one); the 13th should be your new doubly-indirect
block. You are done with this exercise when bigfile writes
65803 blocks and usertests -q runs successfully.
$ bigfile
..................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
wrote 65803 blocks
done; ok
$ usertests -q
...
ALL TESTS PASSED
$
bigfile will take at least a minute and a half to run.
user/usertests.c performs comprehensive testing of all of the Xv6 provided user programs. When you have created a system that is to be updated, you should create a collection of tests that can be run whenever you update the system. This allows you to make sure that you updates did not break any code in the original system. user/usertests.c is the collection of tests for the Xv6 provided user programs, and usertests.c provides a quick version of the tests by using the -q option. Be aware that the -q option is still rather slow on our CPSC server.
Some Hints
- The file kernel/fs.c contains the functions you must update. The functions
are bmap() and itrunc().
- The file kernel/fs.h has been provided for you. The file system
definition of a struct dinode has be updated to reflect the diagram provided above.
Also, the macro defintion of NDIRECT has been updated. Since the number of
direct address has been reduced do 11, the NDIRECT macro defines it to be 11.
- The function bmap() uses a variable named ip, which stands
for inode pointer. The definition is
struct inode *ip
- Make sure you understand bmap(). Write out a diagram of the
relationships between ip->addrs[], the indirect block, the
doubly-indirect block and the singly-indirect blocks it points to, and
data blocks. Make sure you understand why adding a doubly-indirect
block increases the maximum file size by 256*256 blocks (really -1,
since you have to decrease the number of direct blocks by one).
-
Think about how you'll index the doubly-indirect block, and
the indirect blocks it points to, with the logical block
number.
- You will see that the kernel/fs.h provided changed the definition of
NDIRECT to be 11. It was previously 12. This change required
changing the declaration of addrs[] to be
uint addrs[NDIRECT+2]; // Data block addresses
- The definition of struct inode in file.h also uses
the macro NDIRECT for its addrs[] array.
You must update file.h's definition of struct inode and addrs[]
to match that of fs.h's definition of struct dinode and addrs[].
- Since the definition of NDIRECT has been changed, make sure to create a
new fs.img, since mkfs uses NDIRECT to build the
file system.
- If your file system gets into a bad state, perhaps by crashing,
delete fs.img (do this from Unix, not xv6). make will build a
new clean file system image for you.
- Don't forget to brelse() each block that you
bread().
- You should allocate indirect blocks and doubly-indirect
blocks only as needed, like the original bmap().
- Make sure itrunc frees all blocks of a file, including
double-indirect blocks.
- usertests takes longer to run than in previous labs
because for this lab FSSIZE is larger and big files are
larger.
Testing
The file user/bigfile.c has been provided. It creates the longest file it can by
repetitively writing a buf[BSIZE] to the file big.file until the
write() call returns a negative number. The bigfile command
displays the number of blocks written. After you have implemented the
solution, the bigfile command should write 65803 blocks.
If you enter the bigfile command on the original Xv6creates the longest file it can
write is 268 blocks.
$ bigfile
..
wrote 268 blocks
bigfile: file is too small
$
The test fails because bigfile expects to be able
to create a file with 65803 blocks, but unmodified xv6 limits
files to 268 blocks.
Study bigfile.c. You will see that it writes the block number to each block,
and after writing blocks, it reopens the file
and reads the blocks, making sure that each block contains the correct block number.
Problem 2: Symbolic links
In this exercise you will add symbolic links to xv6. Symbolic
links (or soft links) refer to a linked file by pathname; when a
symbolic link is opened, the kernel follows the link to the referred
file. Symbolic links resembles hard links, but hard links are
restricted to pointing to file on the same disk, while symbolic links
can cross disk devices. Although xv6 doesn't support multiple
devices, implementing this system call is a good exercise to
understand how pathname lookup works.
Your Job
Originally, you were to implement the symlink(char *target, char *path)
system call, which creates a new symbolic link at path that refers
to file named by target. Implementing this is rather difficult.
Thus, I have modified this portion of the lab so that you only have to answer questions.
Some Hints
- If you want to get my solution to this problem, just let me know.
- First, create a new system call number for symlink, add an entry
to user/usys.pl, user/user.h, and implement an empty sys_symlink in kernel/sysfile.c.
- Add a new file type (T_SYMLINK) to kernel/stat.h to
represent a symbolic link.
- Add a new flag to kernel/fcntl.h, (O_NOFOLLOW), that can
be used with the open system call. Note that flags passed to
open are combined using a bitwise OR operator, so your new
flag should not overlap with any existing flags. This will let you
compile user/symlinktest.c once you add it to the Makefile.
- Implement the symlink(target, path) system call to create
a new symbolic link at path that refers to target. Note that target
does not need to exist for the system call to succeed. You will need
to choose somewhere to store the target path of a symbolic link, for
example, in the inode's data blocks. symlink should return an integer
representing success (0) or failure (-1) similar to link and unlink.
- Modify the open system call to handle the case where the path
refers to a symbolic link. If the file does not exist, open
must fail. When a process specifies O_NOFOLLOW in the flags
to open, open should open the symlink (and not
follow the symbolic link).
- If the linked file is also a symbolic link, you must recursively
follow it until a non-link file is reached. If the links form a cycle,
you must return an error code. You may approximate this by returning
an error code if the depth of links reaches some threshold (e.g., 10).
- Other system calls (e.g., link and unlink) must not
follow symbolic links; these system calls operate on the symbolic
link itself.
- You do not have to handle symbolic links to directories for this
lab.
24.
Explain soft and hard links. How are they different? How are hard links implemented?
For further information about links (both symbolic/soft and hard links), you can search the Internet or refer to
the man pages for link and symlink.
When performing your background study be sure to study the differences between soft and hard links.
25.
This lab has a symbolic link test program - user/syblinktest.c, which was intended to test your implemenation of symbolic links.
Instead, you will study user/symlinktest.c and document your understanding.
In the file user/symlinktest.c, explain the functions testsymlink() and stat_slink().
26.
Create a design for symbolic links. Design the symlink() system call that creates a symbolic link and open() that opens a symbolic link. Your open() design has to traverse two symlinks.
In your design, you can create/use functions such as the following:
- ialloc() - allocate and return an inode.
- nameiparent() - return the inode of a parent. For example, nameiparent("dir/file") returns the inode of dir.
- dirlookup(inode, name) - return the inode of file "name" in the directory "inode"
- iupdate(ip) - update the inode.
For example, $ echo gusty > file can be designed as follows. You can create other functions.
- ialloc() an inode for file.
- balloc() a data block for file.
- Add the data block to file's inode.
- Write the string gusty to the data block.
- Update the size in file's inode.
- Add the directory entry file and inode to the current working directory.
Testing
$ symlinktest
Start: test symlinks
test symlinks: ok
Start: test concurrent symlinks
test concurrent symlinks: ok
$ usertests -q
...
ALL TESTS PASSED
$
Submit the lab
This completes the lab.
Read Lab Submissions for instructions on how
to submit your lab.
Additional Submission Requirement: You must submit your design for the symbolic links problem in the FS Text Canvas assignment. Since you have handwritten the design in your notebook, you have two options: (1) You can take a photo and submit it, but you must ensure I can read you writing and the photo file is a common format, (2) You can make an electronic copy of you design and submit it as a .txt or .pdf file.