In this lab you will implement a priority scheduler for xv6.
Before you begin lab scheduling,
For this lab, be sure to invoke make as $ make CPUS=1 qemu.
This allows your priority scheduler to demonstrate scheduling with priorities without the complications of multiple CPUS.
In this lab, there are several questions for you to answer. Questions are in boxes with a light orange background. Write each question and its answer in your notebook. You will state the percentage of questions answered on your lab submission.
The Linux grep command can be helpful on some questions. For example, suppose a question asks you about the struct proc. You can discover the definition and uses of the struct proc by issuing the following Linux grep command in the kernel directory.
$ grep "struct proc" *.h
defs.h:struct proc;
defs.h:pagetable_t proc_pagetable(struct proc *);
defs.h:int killed(struct proc*);
defs.h:void setkilled(struct proc*);
defs.h:struct proc* myproc();
proc.h: struct proc *proc; // The process running on this cpu, or null.
proc.h:struct proc {
proc.h: struct proc *parent; // Parent process
proc.h:struct prochist {
% grep "struct proc" *.c
exec.c: struct proc *p = myproc();
file.c: struct proc *p = myproc();
pipe.c: struct proc *pr = myproc();
... lots of matches
sysproc.c: struct proc* p = myproc();
trap.c: struct proc *p = myproc();
trap.c: struct proc *p = myproc();
Fetch the xv6 source for the lab and check out the scheduling branch:
$ git fetch $ git checkout scheduling $ make clean
The files proc.h and proc.c contain the data structures and algorithms used to implement Xv6's process model. The data structure struct proc defines process information that Xv6 uses. When performing Lab syscall, you added members to struct proc. For Lab Scheduling, I have added members to struct proc and code to proc.c.
#define SCHED_RR 0 // Round-Robin Scheduler #define SCHED_PRIOR 1 // Priority-Based Scheduler
The file proc.h defines the enumerated type procstate as follows.
enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
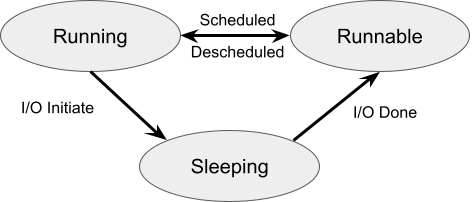
Processes have a state diagram that is summarized as follows.
1. Draw the above diagram in your notebook.
2. Provide two examples of something a process can do that causes it to transition from RUNNING to SLEEPING.
3. Provide two example events that cause a process to transition from SLEEPING to RUNNABLE.
4. There is an arrow in the state diagram labeled with Scheduled and Descheduled. What function in Xv6 performs this arrow?
5. What function in Xv6 performs the transition from Sleeping to Runnable?
6. Why do you think a process cannot transition from Sleeping to Running?
The scheduling algorithm searches a list of Runnable processes, selects the next process to run, and runs it. Running a process involves a context switch, which is described in the next section. The scheduling algorithm performs both the Scheduled arrow and the Descheduled arrows. The arrow labeled Scheduled moves a process from Runnable to Running, while at the same time the arrow labeled Descheduled moves the Running process back to the list of Runnable processes.
You will notice that procstate defines three additional states UNUSED, USED, and ZOMBIE. An UNUSED proc is available to be allocated. A proc is temporarily in the USED state until it is finally aloocated when it becomes RUNNABLE.
7. Look up what it means a Linux process to be in a ZOMBIE state. Write the answer and create a program that results in a process in a ZOMBIE state. Use the Xv6 ctrl-p command to demonstrate your program results in a process that is in the ZOMBIE state. Since the program is such a few lines, hand write the code in your notebook.
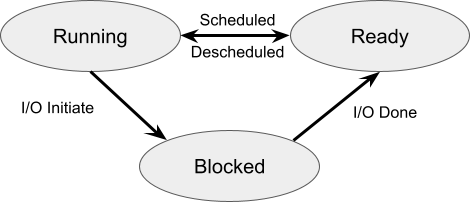
Another terminology for process states is Running, Ready, and Blocked. OS Three Easy Pieces uses this terminology. The following is a process state transition diagram using these terms.
Xv6 supports a maximum 64 concurrent processes, and they are defined in the array struct proc proc[NPROC]; where param.h contains #define NPROC 64, and proc.h contains the definition of a struct proc. struc proc has many members, one of which is enum procstate state;. The function procinit() in proc.c initializes all of the struct proc elements in the array proc[] to UNUSED. An allocated process (allocproc() is briefly in the USED state until it is made RUNNABLE.
8. As stated above the scheduler has a list of Runnable procs. The sheduler uses it scheduling algorithm to select the next proc to run from the list of Runnable procs. Describe the ready list used by Xv6.
9. Why do you think allocproc() used the intermediate state USED? You will have to examine the code to answer this.
The Xv6 scheduler() iterates through the struct proc proc[] array searching for a RUNNABLE process. Once the scheduling algorithm selects a RUNNABLE process, Xv6 performs a context switch from the scheduler to the selected process. Context switches are a key component in operating systems. A timer interrupt causes the scheduling algorithm to run. Consider that the OS is currenting executing process Coletta when a timer interrupt occurs. First a context switch from Coletta to the scheduler must occur. Then, after the scheduler has selected Opal to run, a context switch from the scheduler to Opal must occur. Once Xv6 has booted, the scheduler enters an endless loop searching for RUNNABLE processes and performing context switches to them. The scheduler runs in kernel mode. Xv6 creates the initproc, and the scheduler runs it (i.e., performs a context switch). The initproc creates the sh (shell) process, and the scheduler runs it.
10. When you want to add a new user program to Xv6, what must you do the the Makefile?
11. What code is located in ulib?
12. What code is located in usys?
The following diagrams displays a context switch from a process Coletta to a process Opal.
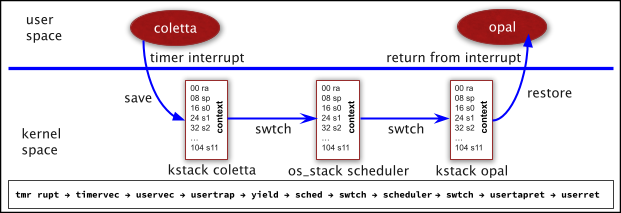
There is a lot to digest in the above simple-looking context switch diagram. The process Coletta is running in user mode, when a timer interrupt occurs, which is the OS interrupt used for a context switch. On the RISCV architecture, the timer interrupt is immediately processed in machine mode by timervec() (in kernelvec.S), which issues a software interrupt that is processed by uservec() (in trampoline.S). The RISCV CPU is now in supervisor mode, but the CPU is still using the page table of Coletta - not the OS page table. The code for uservec() is on the trampoline page, the virtual address of which is mapped in each user proc's page table. Coletta's trampoline page is marked to allow execution in supervisor mode. To refresh your memory on memory layout, you can examine memlayout.h and Figure 3.3 of our xv6 text book, which was part of our page table studies. Having the trampoline page mapped to Coletta's page table allows uservec() to begin executing in supervisor mode prior to changin to the OS page table, which also maps the virtual address trampoline page to the same address. Thus uservec() can switch to the OS page table and continue executing the trampoline code. Before switching to the OS page table, uservec saves all registers in Coletta's TRAPFRAME. Each process has a unique physical page allocated as its TRAPFRAME. Each process's TRAPFRAME is mapped to the same virtual address, which allows uservec() to save the registers. The process's struc proc member p->trapframe points to the trapframe with its physical address, which allows the kernel to access the process's TRAPFRAME using the kernel page table because the kernel's page table maps a virtual address to its corresponding physical address. For example, the kernel's page table maps the virtual page number 0x80000 to the physical page number 0x80000.
13. Given kernel virtual address of 0x80000b0b, what is its corresponding physical address?
14. What is the virtual address of the TRAMPOLINE page?
15. Explain the processing of a timer interrupt in your own words.
16. uservec() in trampoline.S begins execution using a process page table and transitions to the OS page table.
17. Draw Figure 3-4 from our xv6 text book in your notebook.
The Xv6 function scheduler() in the file proc.c implements a round robin scheduler.
18. Explain how the algorithm in scheduler() implements a round robin scheduler. NOTE: The answer is a little trickier than you may think.
You will implement a priority scheduler.
19. Create a design for your priority scheduler. You must complete this before you begin implementing the code for your priority scheduler.
$ testschd 20 3 31
The testschd.c program calls the system call function spoon(), which is exactly like fork(), but spoon() allows you to name the function. The function name is copied into the struct proc member name. Without spoon() all of the processes of testsched would have the name of their parent - e.g., they would be named testschd.
You must implement spoon() before testschd.c will run. Or you can change the calls to spoon to be calls to fork to temporarily run the program, but you must implement spoon() before completing the lab.
Xv6 provides a ctrl-p that shows processes and their states. ctrl-p is similar to
Linux ps command.
You can enter ctrl-p at any time and it displays
The following shows entering ctrl-p while testschd is running. The display shows the
processes pid, priority, state, and name. Notice the various states of sleep, runble,
and run. This was done on a Xv6 build with CPUS=1 so there is only one process in
the state run. Also notice how Coletta and Opal alternated between states
run and runble.
20. Given the above two instances of ctrl-p, what scheduler (round-robin or priority)
is running and why?
The version of the kernel provided with this lab has a system call prochist() that displays
the process history captured in the prochist[] circular buffer. You should examine the
implementation of prochist() to determine it calls the function prochistory(), which
is in proc.c. User programs can make the prochist() system call. Additionally,
you can connect ctrl-g to prochistory(). I have done this in my demonstration
version of Xv6. For this lab, you must do the same. Once you have implemented ctrl-g, you can enter it
at any time to view the process history, which shows the first line as
21. Explain in your own words how the circular buffer of process history is implemented.
22. The first line printed by the system call prochist() shows
various statistics. You will have to study the code to answer these questions.
You must implement the spoon() system call function.
The following shows running testschd using my priority scheduler.
If you examine the testschd.c code, you will see the parent calls the system
call - prochist() after the children are finished.
Items to notice in the printout.
23. Describe what would happen in a priority scheduler in the following scenario.
24. What happens when you run your priority scheduler on the normal build, which has four CPUs?
The normal build is created by
Update user/testschd.c to include a fourth process: Penny. Assign Penny a default priority of 53.
Update Xv6 such that entering ctrl-g from the keyboard displays the process history.
Once you have completed this, you can enter ctrl-g to see the process history at anytime just like you can
enter ctrl-p at anytime to the processes and their states.
25. What kernel .c file contains the code for processing
ctrl-p and ctrl-g?
Update Xv6 to include two systems calls: setpriority and getpriority.
From the user program perspective, the function protypes are
When a process calls setpriority, the argument passed is placed in the member
priority of its struct proc.
When a process calls getpriority, the value in the the member
priority of its struct proc is returned.
Update Xv6 to include a int spoon(char*) system call.
26. Both fork() and spoon() have the following code.
27. Both fork() and spoon() have the following code.
28. Both fork() and spoon() have the following code.
Update Xv6 to include a priority scheduler with the follwoing attributes.
After you have finished your priority scheduler, run
Examine
Scheduler Tester - ctrl-p for a sample of what you should see.
The following diagram shows various scheduling algorithms. You will select a Timeline in your answers to questions below.
29. Describe a FIFO scheduler. Use a Timeline from the above diagram as part of your description.
30. Describe a shortest job first scheduler. Use a Timeline from the above diagram as part of your description.
31. Describe a shortest time to completion scheduler. Use a Timeline from the above diagram as part of your description.
32. Describe a multi-level feedback queue scheduler.
33. Describe a Linux completely fair scheduler.
This section does not have any questions, but I usually include a question about fair schedulers (in particular the Linux Completely Fair Scheduler) on the Final Exam. One of my favorite questions from past exams involves comparing LCFS to the lottery or stride scheduler. Another favorite question is something similar to the LCFS practice problem given below.
This section provides a cursory treatment of the schedulers. You will have to be sure to read
OSTEP Ch 8: MLFQ and
OSTEP Ch 9: Lottery
and/or ask questions in class about these schedulers.
A fair scheduler attempts to be fair to processes. Fair means that processes get to run their fair amount based upon some priority.
The priorities can be assigned by individuals (people) or computed based upon the history of the process's execution. The MLFQ uses execution history to assign priorities. Lottery, Stride, and Linux Completely Fair schedulers rely on individual to assign process priorities.
A scheduler runs a process for a timeslice (also called a quantum). A timeslice is a specific number of miliseconds.
For example, timeslice may be 45, 50, or 100 miliseconds.
The Multilevel Feedback Queue scheduler uses execution history to establish processes' priorities. All processes begin with the highest priority. If a process consumes its entire timeslice, its priority is lowered. This is done with multiple levels of priority queues.
OS Three Easy Pieces, Ch 8: MLFQ describes the Multilevel Feedback Queue scheduler.
The following the MLFQ rules are from Chapter 8, page 10.
OSTEP, Ch 9: Lottery describes the lottery scheduler.
Processes are assigned tickets that allocate the process's share of the CPU.
For example, if there are two RUNNABLE processes - P1 and P2, where P1 has 100 tickets and P2 has 200 tickets, the P2 runs twice as much as P1.
The algorithm is really simple, and it is given by the following.
OSTEP, Ch 9: Lottery describes the stride scheduler.
The stride scheduler is a deterministic fair scheduler.
OSTEP, Ch 9: Lottery describes the Linux Completely Fair scheduler.
LCFS is unique in that it assigns longer time slices to processes with higher priorities, whereas,
the lottery and stride fair schedulers run processes with higher priorities more time slices.
The priority in LCFS is its nice value. Linux has a nice command and a nice() system call that can
be used to adjust the nice values of processes.
The nice values range from -20 to 20, which -20 having the highest priority and 20 having the lowest.
The nice value is used to select a weight that is used in a forumla to compute the process's timeslice.
The value schedule latency (schedlatency) is the number of miliseconds that divvied among the processes that are RUNNABLE.
For example, if schedlatency is 100 milliseconds and four processes, each with the same nice value of 0, are RUNNABLE,
each would be allocated a 25 millisecond timeslice.
Suppose there are N RUNNABLE processes, The formula to compute the timeslicek for processk is given by the following.
timeslicek =
weightk / sum(weighti for i=1..N) * schedlatency
The formula may seem intimidating, but an example exposes the simplicity of the formula.
Consider there are two RUNNABLE processes, P1 and P2 and the schedlatency is 100 milliseconds.
P1 has a nice value of -5, which is a weight of 3121.
P2 has a nice value of 0, which is a weight of 1024.
You should observe that P1 has a weight (priority) that is approximately 3 times that of P2.
The formula will assign a timeslice to P1 that is approximately 75 millisecond and a timeslice to P2 that is 25 milliseconds.
The exact values computed by the formula are the following.
Virtual Runtime is the last piece of this puzzle. When it is time to select the process to move from RUNNABLE to RUNNING,
LCFS selects the process with the smallest virtual runtime, which is defined by the following formula.
vruntimei = vruntimei + weight0/weighti *
runtimei
It is important to observe the the vruntime of the two processes P1 and P2 increase exactly the same, which is 24.7. This means that the algorithm is selecting the one with the smallest vruntime, will be a round-robin between the two. This means that P1 runs for 75ms, P2 runs for 25ms, P1 runs for 75ms and so on. Thus achieving the desired fairness when P1 runs 3 times as much as P2.
This problem considers a Linux Completely Fair Scheduler that has the following table of nice values.
Use the renice command with appropriate nice values to change the nice value of processes 2021, 2022, and 2023 such that process id 2021 runs twice as much as process id 2022, and process id 2022 runs twice as much as process id 2023. The nice values may not exactly translate to twice as much, but they can be close. Add commentary to your answer that explains what you are doing and why.
This completes the lab.
Please pay attention to this section as you must perform some slightly different steps.
Scheduler Tester - ctrl-p
proc_id priority state name
$ testschd
ctrl-p
1 0 sleep init
2 0 sleep sh
3 100 sleep testschd
4 50 runble Coletta
5 51 run Opal
6 52 runble Florence
ctrl-p
1 0 sleep init
2 0 sleep sh
3 100 sleep testschd
4 50 run Coletta
5 51 runble Opal
6 52 runble Florence
Scheduler Tester - ctrl-g
Tmr Rupts: 250, Sch Loops: 212295, Swtch Run: 210, Swtch New: 13, Switch Old: 182, Swtch sh: 15
Followed by a sequence of lines, each of which contains
index: cpu proc_id priority name priority
Sample testschd.c Output for Round-Robin Scheduler
The following shows running testschd using the Xv6 round-robin scheduler.
If you examine the testschd.c code, you will see the parent calls the system
call - prochist() after the children are finished.
Items to notice in the printout.
$
Sample testschd.c Output for Priority Scheduler
$ testschd
Parent Sleeping - let children get priorities set.
Child Coletta:4, priority 0!
Child Coletta:4, priority 50!
Child Opal:5, priority 0!
Child Opal:5, priority 51!
Child Florence:6, priority 0!
Child Florence:6, priority 52!
Starting child Coletta:4
Starting child Opal:5
Starting child Florence:6
Child Florence:6 with priority 52 has finished!
Child Opal:5 with priority 51 has finished!
Child Coletta:4 with priority 50 has finished!
All children have finished!
Tmr Rupts: 224, Sch Loops: 121268, Swtch Run: 238, Swtch New: 15, Switch Old: 209, Swtch sh: 14
0: 0 1 initcode 0
1: 0 2 init 0
2: 0 3 testschd 0
3: 0 4 Coletta 0
4: 0 5 Opal 0
5: 0 6 Florence 0
6: 0 3 testschd 100
7: 0 6 Florence 52
8: 0 3 testschd 100
9: 0 6 Florence 52
10: 0 3 testschd 100
11: 0 5 Opal 51
12: 0 3 testschd 100
13: 0 4 Coletta 50
14: 0 3 testschd 100
How to Make - make CPUS=1 qemu
To properly test your priority scheduler, you want to run it on one CPU. To do this,
$ make CPUS=1 qemu
$ make qemu
Problem 0: Update testschd.c
Some Hints
Problem 1: Implement ctrl-g
Some Hints
Problem 2: Implement the setpriority/getpriority System Calls
int setpriority(int);
int getpriority(void);
Some Hints
Problem 3: Implement the spoon() System Call
Some Hints
// copy saved user registers.
*(np->trapframe) = *(p->trapframe);
How does this one-line of code save all of the user registers from one trapframe the new proc's trapframe?
// Cause fork to return 0 in the child.
np->trapframe->a0 = 0;
Recall that fork() and spoon() create a child proc and returns 0 for the child and the child's PID for the parent.
a) Explain how this line returns a 0 for the child proc.
b) What line of code returns the PID for the parent?
// increment reference counts on open file descriptors.
for(i = 0; i < NOFILE; i++)
if(p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
Why are these reference counts for open file descriptors incremented?
Problem 4: Implement a Priority Scheduler
else if (scheduler_policy == SCHED_PRIOR) {
YOUR CODE HERE
}
Currently this block contains a duplication of the round-robin scheduler.
Some Hints
$ testschd
and enter ctrl-p several times to demonstrate processes and their states.
Diagrams of Various Schedulers
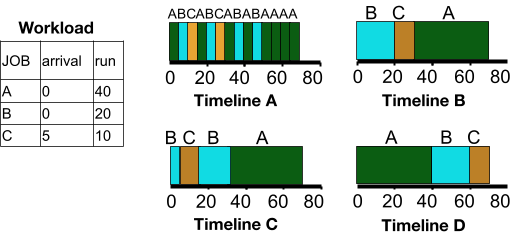
Fair Schedulers
Multilevel Feedback Queue Scheduler
Lottery Scheduler
int winner = getrandom(0, totaltickets);
node_t *current = head;
while (current) {
counter = counter + current->tickets;
if (counter > winner)
break; // found the winner
current = current->next;
}
Over time, the processes with more tickets will win the lottery more times that processes with less tickets.
This means the processes with more tickets will run more timeslices the the processes with less tickets.
However, in a short sampling period, the lottery scheduler may not exhibit the desired fairness.
Since it relies on a random number, the lottery scheduler may run a ticket with less tickets more than it should.
Stride Scheduler
Linux Completely Fair Scheduler
static const int nice_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
0 + 24.7
0 + 24.7
LCFS Practice Problem
static const int nice_to_weight[40] = { // negative – higher prior
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
Your system has three computational processes with process ids 2021, 2022, and 2023 that are executing with nice values of 0. They are running for a long time. You can change the nice value of a process using the renice command. The following changes process id 2021 to have a nice of -1.
$ sudo renice -n -1 -p 2021
Submit the lab - Different than past lab submissions
$ git archive --format=tar HEAD | gzip > lab-scheduling-handin.tar.gz
In a normal submission, you would enter $ make tarball; however, the Makefile for this lab does not have that target. You must create the zip file yourself.